


3. maj 2024,
kl. 13.00-18.00

3. maj 2024
IT KARRIEREDAG
Hvor virksomheder og studerende mødes og taler om fremtidige karrieremuligheder

Rekord i ansøgertal
Flere end nogensinde før har søgt ind på DIKU via kvote 2
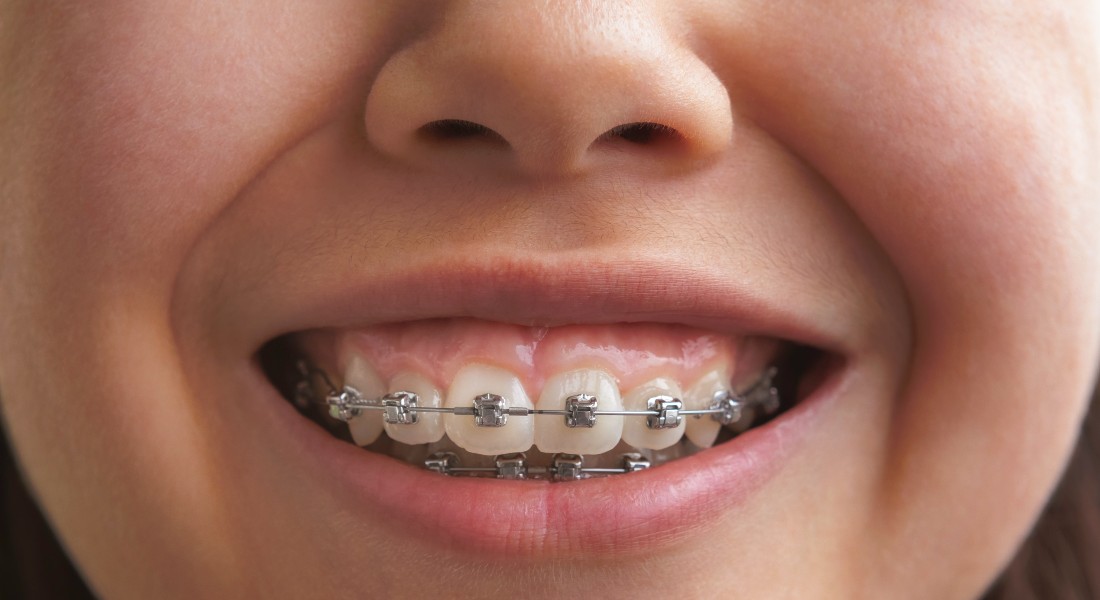
Kunstig intelligens
Rettelse af tænder? AI kan nu hjælpe med placering af bøjle

ROBOTTER
Forskningsprojekt skal udvikle intelligent robot som kan screene for tarmkræft